Our routing has been used in a range of academic and transport planning projects.
Because our routing aims to emulate as close as possible the route that a knowledgeable cyclist would take, creating a matrix of route results between sets of Origin<>Destination (OD) pairs facilitates various interesting statistical analyses of the quality of cycle infrastructure in an area.
For instance:
- Comparing the circuity of the quiet routes between points, compared to the fast routes, can be used to determine the extent to which cycle infrastructure is of such quality as to enable direct routes.
- Comparing the average crow-fly distance vs cycle route distance between points can be used around a city to determine the comprehensiveness of a cycle network.
To aid this, we have a batch routing interface, enabling a matrix of route results to be generated.
By setting either a set of known points, e.g. cycle docks in a city, or defining a rectangular region that we will automatically divide for you into boxes at a specified resolution, our batch routing interface will plan all the A-B combinations, and create a CSV file of all the results.
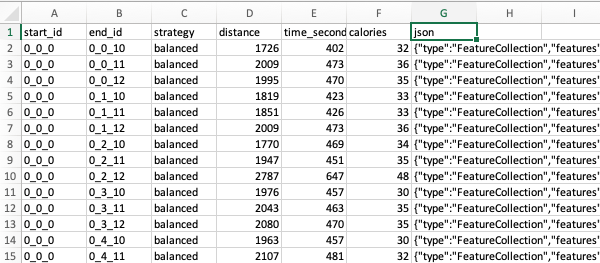
The batch routing is really just a front-end that marshalls requests to our main routing API. We strongly encourage use of the batch UI rather than writing scripts to do the same, as this will generate routes more efficiently, not least because parallelisation is in place, and it sets various API flags sensibly to avoid unnecessary CPU steps.
A large number of options are available in the batch UI – here are just some:
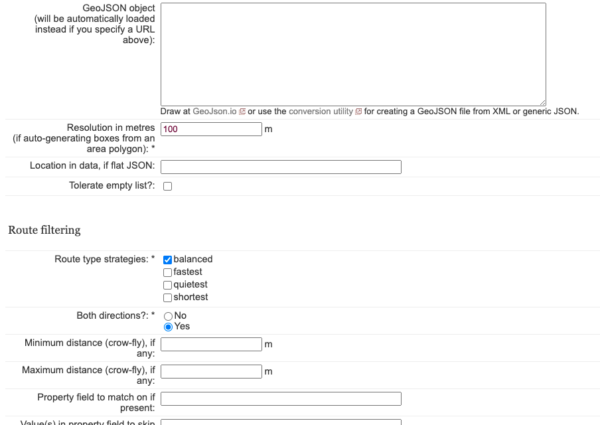
To use the batch routing, you need an API key (and therefore a user account).
The batch routing can result in tens/hundreds of thousands of route requests, and so we expect users to set options sensibly. It will quickly exceed the standard free daily limits specified in our API usage policy.
We will generally grant free usage to hobbyists and researchers on smaller projects, as we are eager to encourage advocacy work. For commercial use, use by local authorities and their consultancy companies, and researchers with significant funding, we expect the use of an SLA (paid) key, as server resources have actual costs to us.
Update, February 2023: There is now also an API interface to the batch routing.